
Detecting compressor valve failures before they drive unplanned downtime
Why fixed alarm thresholds miss developing valve issues
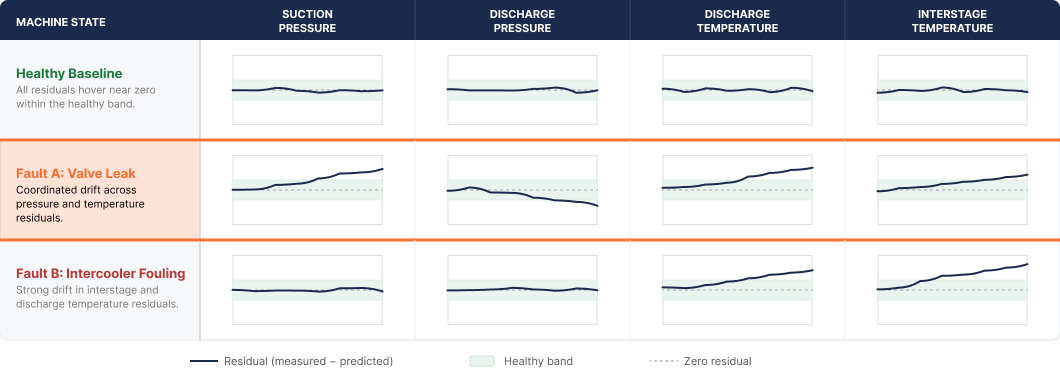
Unfortunately, compressor valve failure detection is technically a poor match with fixed-threshold monitoring. A leaking suction valve doesn’t show up as “discharge temperature exceeded 300°F.” It shows up as a small increase in suction temperature, a small drop in capacity, a shift in the pressure ratio across that throw, and a small change in stage horsepower demand. Each of those individual changes sits inside the normal operating range of a healthy machine, which is what makes them challenging to detect. The pattern across them is what’s diagnosable.
Fixed thresholds also can’t account for operating mode. A compressor running at half load has different normal pressure ratios, different normal cylinder temperatures, and different normal capacity than the same machine at full load. A valve leak that would be obvious at half load might be completely invisible against a full-load threshold. Most monitoring systems handle this by setting the threshold wide enough to never false-alarm, which by definition means they also miss the early-stage faults.
By the time a valve failure crosses a fixed alarm threshold, it’s usually advanced enough that the operational options are very limited. Either you trip the machine and lose production, or you keep running and risk a more expensive secondary failure.

What catches valve failures earlier
Effective compressor valve failure detection requires three things working together. First, a model of expected behavior that accounts for current operating conditions, so the residuals (measured minus predicted) respond to actual degradation rather than load changes. Second, multi-signal pattern matching, because valve faults express across pressure, temperature, capacity, and horsepower simultaneously. Third, fault-mode-specific output, so the alert tells the engineer which valve, which throw, and what type of failure (suction leak, discharge leak, excessive power loss) is most likely.
With those three layers, valve degradation becomes detectable at the point where the residual pattern first deviates from healthy operation, not at the point where one signal crosses a static limit. In practice this often translates to weeks of additional lead time.
What this looks like in the field
On an Ariel reciprocating compressor at a major U.S. Oil & Gas operator, TruPrognostics™ AI surfaced a developing loss of efficiency more than 40 days before the OEM’s built-in alarm system would have flagged anything. The model returned three plausible fault modes (suction valve leak, discharge valve leak, excessive valve power losses) each with a confidence score and the multi-signal evidence behind it. The customer’s reliability team deployed an analyst who confirmed a leaking discharge valve, and scheduled the valve replacement during the next planned maintenance window. The compressor was serviced in a controlled outage with no unplanned shutdown.
The 40+ day lead time matters because it changes the work plan. Enough time to procure parts, coordinate operations, and pull the machine offline during a scheduled event rather than respond to a trip. That’s the operational difference between “early detection” and “detection that arrives in time to be useful.”
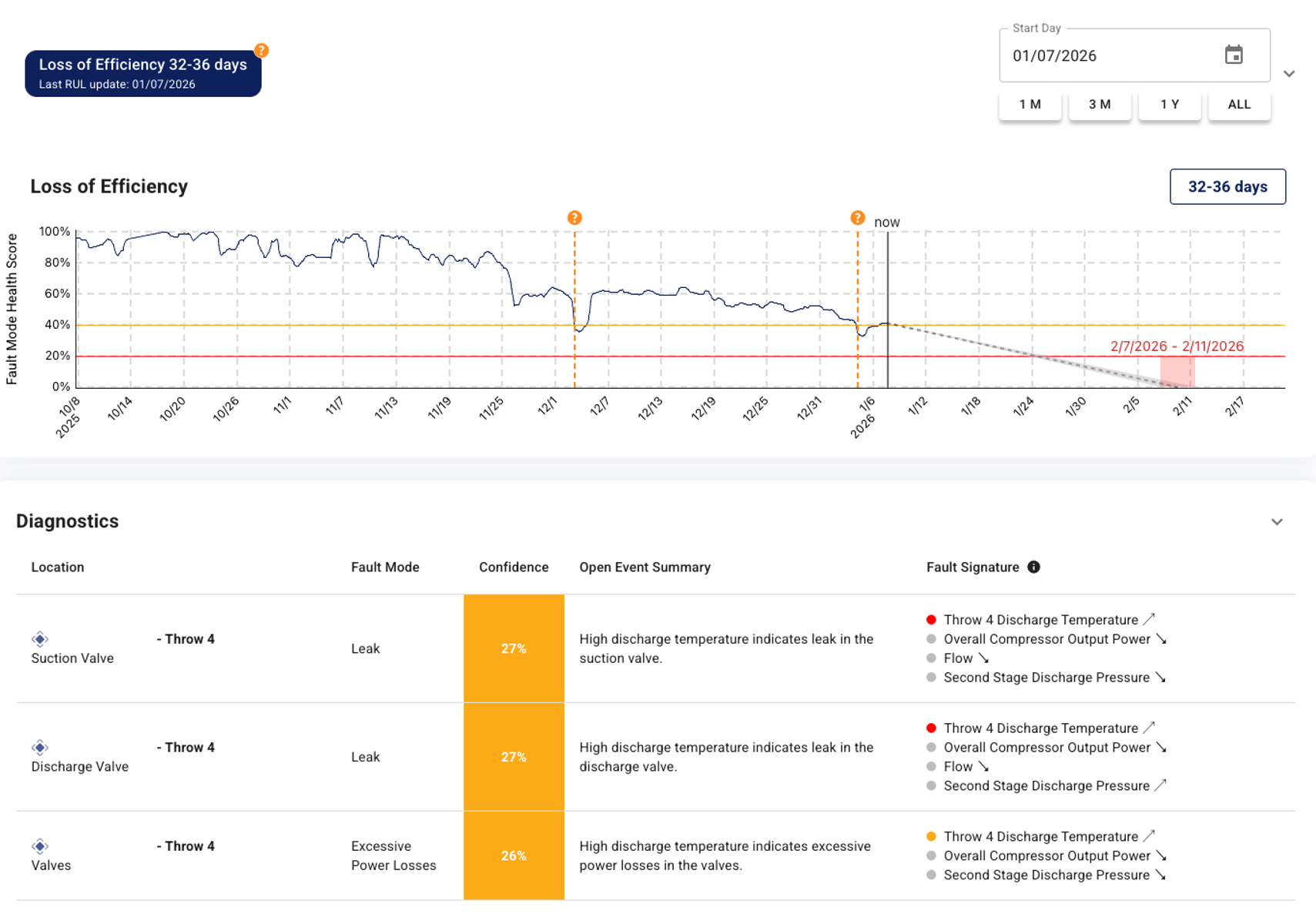
The full case, including the screen-by-screen of what the diagnostic output looked like and how the model surfaced the fault evidence, is on page 13 of our compressor predictive maintenance technical guide. Download the full technical guide here.
